

Monday, October 25. 2010
Using Cassandra with EJB Technology

The past week Eric, a french reader of the blog, contacted me because of my old Cassandra entry. He was trying to get some help in how to implement an Enterprise Java Bean for the NoSQL database. As I explained in the Terminal Services posts the portlet used Thrift and Cassandra to store the application tree which was shown in the series. I am going to present the same solution but replacing the portlet with an EJB 3.1 / JSF 2.0 web application. The idea of this post is explaining the whole process.
First of all the Cassandra data model was designed. If you remember, the Terminal Services portlet is a tree very similar to a file system. Any item can be a folder or an application. Folders can contain any number of other folders or applications, and applications are leafs which contain the RDP definition file (the file which is downloaded to launch the Terminal Services client program). Following the ideas presented in the old Cassandra post only two simple columns were needed.
- Applications: The applications column family will contain all the applications and folders. The key will be the complete and uppercased path of the application (for example /APPLICATIONS/SKYPE) and the values will represent different data. More precisely the columns will be the following:
- name: application name to show (Skype).
- description: application description.
- icon: 16x16 PNG icon.
- type: app or folder.
- rdp: rdp file to startup this application (only for apps).
Applications: { // ColumnFamily
/INTERNET: { // key
name: Internet
description: Internet applications
icon: 0x19EA14...
type: folder
},
/INTERNET/SKYPE: { // key
name: Skype
description: VoIP client application (www.skype.com)
icon: 0x56FA12...
type: app
rdp: 0xA4326A...
}
...
}
- ApplicationStructure: This other column family just cover the folder structure which is missing in the other one. This column is quite simple, the key continues to be the path of the folder in uppercase and the values are its children (path and name of every child). This column family gives an easy way to access all the children of a specified folder.
ApplicationStructure: { // ColumnFamily
/APPLICATIONS: { // key
/APPLICATIONS/INTERNET: Internet
/APPLICATIONS/PAINT: Paint
},
/APPLICATIONS/INTERNET: { // key
/APPLICATIONS/INTERNET/PIDGIN: Pidgin
/APPLICATIONS/INTERNET/SKYPE: Skype
}
...
}
In order to create the EJB which manages applications (and folders) the idea is just creating a bean which handles basic CRUD operations for applications. This class is called CassandraManagerEJB. In the previous posts this class was a POJO (liferay was deployed inside a tomcat and EJB technology was unavailable) that has been now converted into a Singleton Enterprise Bean. Another class called Application represents any application or folder with typical getters and setters. Obviously the CassandraManagerEJB receives objects of this class and transforms them into thrift mutations and columns for writing and vice-versa for reading. There is a special folder keyed by "/" for the root path. The EJB uses commons-pool to treat Thrift connections inside a pool. The three main methods in the EJB are the following:
- readApplication: Reads any application from the Cassandra repository. The application or folder path is passed to the method. The attributes to read can be also specified in order to not read all of them. But it also receives a parameter to specify how the children is retrieved:
- NONE: No children are returned, the column family Applications is the only one read.
- ONLY_NAMES: The application is also read from the ApplicationStructure column family and only its data is filled in the children list (path and name).
- FULL: After reading the children from ApplicationStructure all of them are also got from the Applications column family. So now all the specified attributes are filled in the children list.
- RECURSIVE: The method is called recursively to retrieve all hierarchy with all attributes specified, from the path passed to the bottom.
- createApplication: Creates or updates an application or folder. This method do not let create folders with children (for folders is just like mkdir command), application names cannot contain '/' character (only root can do that) and the specified parent must exists previously in Cassandra repository. If the application object passed does not follow these rules an Exception is thrown.
- deleteApplication: Deletes an application or folder. If the application does not exist or it is a folder with children the method throws an exception (again it can be considered like a rmdir command in case of a folder).
I tested the web module deploying it inside a J2EE6 compatible glassfish v3 application server. So the EJB is annotated to be a Singleton and an application scoped named object, this way the EJB can be injected using Context Dependency Injection (CDI). Remember the beans.xml file must be created to make WELD (CDI implementation) start to work. I recommend to read this post to know more about the differences between CDI and EJB injecting techniques.
The JSF part will use the created enterprise bean to display all the tree. There is only one managed bean which is called ApplicationTreeBean but it is accompanied by some helper classes. This JSF bean uses injection to get the Singleton EJB and is also annotated as named to be injected into index.xhtml facelet like a session scoped bean. The JSF part can be more or less complicated but it just presents the application tree we saw in the Terminal Server entries (see image below).
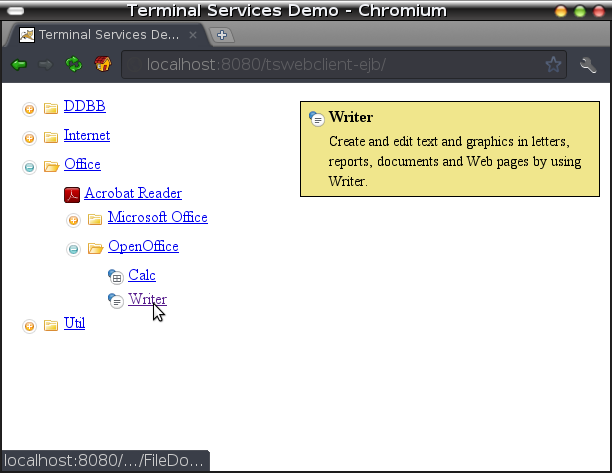
As all of you can see this way of integrating Cassandra into EJB 3.1 technology is very very straight forward but, not being an expert in Cassandra, I think it is the most suitable nowadays. Remember all Cassandra stuff presented here uses the inflexible Thrift client (I chose it cos I wanted to learn Cassandra internals), there are some more java clients out there and surely they are friendlier. Here it is the whole Netbeans project just in case (libraries have been deleted to save space).
When I talked all this stuff to Eric, he advised me there is a project called Kundera (I have just realized it is listed as Cassandra client in the previous link) which is trying to implement a JPA provider for Cassandra (see the following post). At first moment I think it makes no sense, the Java Persistence API is tightly coupled with SQL (it can be said it was designed to cover SQL databases) and, therefore, not very suitable for a NoSQL repository like Cassandra. The weekend I spent some time trying to figure out how, for instance, the queries are performed. Kundera mixes Cassandra repository with Lucene indexing engine and, this way, some little queries can be performed against the indexes. Looking into relations (many to many, one to many, one to one,...) I saw some of them are still not implemented, but this point is less problematic cos developers could (more or less) follow the same ideas I commented in my previous entry about Cassandra. So, despite of my initial skepticism, the project has at least some sense. I still believe the idea is a bit farfetched but I have to admit they are implementing the same solution I would have used in a supposed Cassandra project. If you remember I already talked about mixing Cassandra and some indexing engine like solr (Lucene based) to get a robust result.
Good job guys! Continue surprising me!
Nice post. Just to update you that now Kundera provides support for all type of associations and as well as so many other feature like(polyglot persistence etc).
Take a look at : https://github.com/impetus-opensource/Kundera
Comments