

Saturday, June 14. 2014
Updating the old RDP portlet (Part II)



In a previous entry the updating process of the old RDP portlet was starting. The main new idea is using the FreeRDP project as the local program which launches the Remote Desktop / Terminal Services applications. This project presents all the features the portlet needs (RemoteApp for displaying the non-local applications seamlessly in the user's desktop, the gateway to use RDP over HTTPS and managing exported RDP files) but some of them are just supported in the beta version 1.1 and, in general, they need some love for polishing final details.
This second entry is dedicated to the portlet itself. The portlet was originally developed in the times that JSF 2.0 was being introduced and the technology was starting to be supported inside a portlet. Besides, instead of using a normal relational database, Cassandra NoSQL was used. Therefore the portlet used some curious technologies and projects which have been improved a lot since that time and, I think, some little summary is required.
The Cassandra project has been moved from version 0.6 to 2.0.7 and now everything is different. The old thrift client library (which was explained in detail in another entry of this blog) is now deprecated and a new CQL (Cassandra Query Language) client is recommended. This language is much more similar to standard SQL and working with it in java is easier for developers with experience in JDBC.
Another important piece of the portlet was the portletfaces-bridge, the library that made possible the use of JSF 2.0 inside a portlet. In the old entry this library was in alpha state but now it is part of the liferay community. Besides it is bundled with more libraries in a project called liferay faces. Therefore the bridge is now stable and the only feature which is quite new is CDI. The Context Injection was being introduced in the last versions of these libraries.
Finally the liferay portal is updated from 6.0.2 to 6.2 version. It is a less important change because a portlet is standardized enough to move smoothly from one version of liferay to another.
With all the information provided it is easy to understand that the portlet has been practically re-developed. The Cassandra manager (the class that interacts with the NoSQL database) changed from using the old thrift to the new CQL library. All the beans use the new CDI technology. And finally everything were updated to the new versions. There were also some changes because liferay (or the portlet bridge) does not support in-line images and constantly throws annoying errors with those types of links (the exception thrown was the same that is commented in this forum entry because the link of a in-line image has a uri of type data:image/png;base64,...). The solution is now using servlets for downloading icons and RDP files (I have re-used this fabulous file servlet coded by balusc). Here it is the link for the netbeans project for the tswebclient2 portlet.
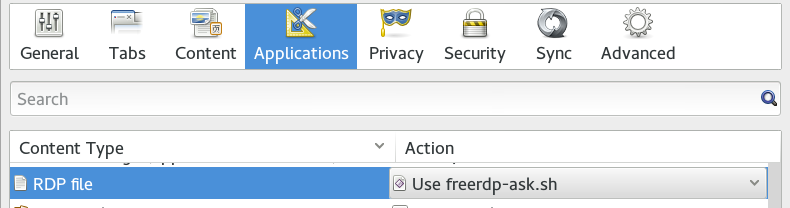
And finally it is needed to change the script used to launch the FreeRDP command. In the past I did a horrible python script that parsed the RDP file and lauched the rdesktop application with the corresponding command line options. Now I have just created a little shell script that only requests the login information (domain, username and password) using zenity. Again it is very improbable and a real solution needs a better launcher. Here it is the freerdp-ask.sh script. Using firefox / iceweasel the script should be chosen to open RDP files (see the following image in which I configured iceweasel to always open those files with the script in the Edit → Preferences → Applications tab).
A video is presented below. A user accesses to the portal using iceweasel in a linux box. The portlet is displayed in the second tab of the portal. The mspaint application is clicked and immediately the script asks for the login information. Once the information is introduced the FreeRDP command is executed against the gateway server. As in the previous entry the nasty shifted cursor issue happens.
This is the last entry of a new series about Remote Desktop or Terminal Services. I tried to improve the previous solution, which was very limited in linux clients, with a new project called FreeRDP. Now the solution seems promising but it is still not ready for a real deployment. It is needed that the FreeRDP project supports RemoteApp feature and understands RDP files flawlessly. (It would be wonderful that the program would open a RDP file without the need of options, domain and username options should be used for gateway and host servers. A way of specifying the password somehow or, at least, requesting it graphically would be nice too).
Remote Regards!
Tuesday, April 5. 2011
High Availability in Application Servers (sequel)
In the previous entry a study about High Availability (HA) in Application Server was done. The main reason for this study was checking how proper an in-memory repository (like membase) is for session management. I found memcached-session-manager (MSM), a session manager for tomcat and memcached, and, for that, I performed a benchmark of the three typical HA solutions using tomcat. In the comments section Martin Grotzke (the main developer of MSM) pointed out that, if mod_jk had been configured sticky, the proper behavior of MSM was also to be sticky. I want to explain that my understanding of the third scenario (a external repository is used to save sessions) consists in that the new backend (JDBC, in-memory or whatever) has to be a complete replacement for session management. This way it should be accesseded twice in every request (first to get the session and then, if session is modified, to save changes). This is the reason I configured MSM non-sticky, but obviously this is the most demanding configuration and quite weird (sticky mod_jk but non-sticky MSM is something clearly useless in a real deployment). Finally I have included the complete sticky benchmark to compare all results fairly.
The MSM project page explains the differences between sticky and non-sticky configuration. When tomcat servers are accessed in a sticky way MSM can assume that, if it has an active session, the session is up to date (cos no other server can modify it). Therefore sticky MSM configuration saves all gets (except in the first request, when there is no active session it has to check if it was previously created in a failed server). Besides MSM seems to use only one object in sticky configuration and two in non-sticky (session itself is obviously always managed but a kind of validity object is also managed in non-sticky implementation), so this fact saves some gets and sets too. In summary, there is a lot less work to do in sticky than in non-sticky configuration. Do not forget a get/set also represents a serialization/de-serialization process.
The MSM/membase sticky solution presents the following numbers. I also show the same charts and graphs of the previous entry:
- Average and 90% Line time (four configurations).
- New graphic results from JMeter for sticky scenario.
- Membase statistics page for this new benchmark.
- CPU utilization in both virtual boxes (all scenarios).





If you see the numbers of sticky configuration (8ms average request time and 14ms for 90% line time) are very similar to the replication cluster, and half a way between simple load balancing and SMS non-sticky. It is quite logical, more or less, half of the work is not necessary. Looking at CPU percentage the new sticky architecture is around 16% (tomcat process consumes a bit less than in replication scenario but membase adds another 4%). So, again, everything is as expected and it is clear that when this solution was mature enough it would be very very competitive with replication cluster but more scalable. All the options have been benchmarcked and studied, as I said before, now it is fairer.
Cheerio!
Saturday, April 2. 2011
High Availability in Application Servers
Today entry, despite it is not a typical topic for me, is about an architectural decision: High Availability (HA) in Application Servers. Actually this entry comes out because I have been seeing these days several solutions which involve a in-memory repository in order to get a clustered session-aware Application Server infrastructure (for example this glassfish + coherence presentation). So I decided to study this new solution more deeply. The entry is divided in three different sections: presentation of some HA theory in Application Server world, preparation of a demo and some benchmark results.
CONCEPTS
As always some concepts are needed before the entry goes into the substance. Mainly Application Servers have three different clustered solutions.
Load Balancing + Stickyness
The first and more easy clustered solution is just a setup with two or more applications servers which receive clients in a sticky way. When I say stickyness I refer to the fact that when a user request has first sent towards a specified server (and the java session has been created in this server) the load balancing element always sends his future requests to the same server. This way the session is maintained in only one server but everything works as expected.
In this scenario there is no special session treatment and, therefore, if one application server dies all its sessions (clients) are lost. The balancer will detect the server has fallen and all new requests will be redirected against another server but, as sessions are stored individually, the user will have to re-login and previous work (in a shopping cart application for instance) could be lost.
As you see this solution is very very simple. There are lots of load balancers solutions (software or hardware) and almost all of them support stickyness (using jsessionid tracking cookie) and server status checks. Stickyness can also be used in the other two solutions and, in fact, it is usually recommended.
Load Balancing + Session Replication
The second solution tries to solve the session lost problem of the previous scenario. Many application servers (all famous ones at least) implement a in-memory session replication. This way when a request modifies any attribute in the session these changes are sent to the rest of servers and, consequently, session is always up to date in all of them.
This solution solves the main problem but it is not absolutely safe. Some problems are the following: all sessions are in all serves (this is the main one, think about a ten server cluster with thousands and thousands of sessions), replication is not immediately done, performance drops when a lot of sessions are involved or they are very big and, if all servers die unexpectedly, they are also lost.
Load Balancing + HA Storage
The final solution is to use another persistent element to store sessions (Application Server can save sessions only in the repository or in both sites, its own heap and in the new repository). This solution has two main problems, the High Availability feature is moved from Application Servers to the external repository and the performance penalty of storing and retrieving any session may be major.
DEMO
The third solution presented before used to be not very common, mainly because the repository for storing sessions traditionally was a database, which represents a severe performance impact and a clustered database was also needed (you know, the box was worth more than its contents). So usually AppServer HA solutions were reduced to the first (when session lost was not a decisive penalty) or the second scenario (when a session-aware cluster was really needed). Nevertheless, after memcached, the in-memory backends are getting more and more popular and this kind of external repositories can solve, in theory, all the typical problems of JDBC stores. When I heard about this idea (as I commented in the beginning of the entry some commercial Application Servers are starting to offer this solution) I checked if there was any open source implementation for doing the same and I found the memcached-session-manager or MSM project. MSM honors its name and it is exactly that, a session manager for tomcat (6 and 7) and memcached. So the rest of this chapter I am going to explain how to setup the previous three scenarios using tomcat.
Obviously a distributable application is also needed for testing. For that I am going to merge two Web Modules (WAR files). On the one hand, the typical glassfish example clusterjsp application, some JSPs which are very useful to check if Load Balancing and Clustering is working. On the other, the ServletBenchmarck, a quite well thought application to bechmark Servlet engines. I have added the JSPs of clusterjsp inside ServletBenchmark war file so I can test individually and benchmark at the same time (here it is the war file I deployed inside tomcats).
Tomcat + Apache2/mod_jk
For the first scenario typical mod_jk balancing is going to be used. The mod_jk is a module for Apache2 that interacts with tomcat servers using AJP 1.3 protocol. It supports load balancing, server checks and stickyness. I installed two debian Squeeze boxes using KVM virtualization. Then I setup two apaches and two tomcats with stickyness enabled, debian packages have been used for everything (there are a lot of installation guides over the internet, for example this one). Here it is my workers.properties if you want to check it out.
With this configuration the following video is presented. When I access apache the mod_jk module redirects my request against one of the tomcats. Using clusterjsp page some attributes are added to the session, as configuration is sticky, same tomcat is always accessed. To test Load Balancing I kill the server which is being used. As you see the other tomcat takes the control but session is empty as expected.

Tomcat + Apache2/mod_jk + Session Replication
The second scenario can be easily implemented because of cluster tomcat feature. This configuration makes each tomcat Server to broadcasts topology and session changes to other servers in the cluster (it seems tomcat uses multicast for spreading changes). In order to configure tomcat inside a cluster only some minor changes in server.xml are needed.
With this setup now the video is better. After I kill the first accessed tomcat and mod_jk redirects my request to the other one, my session is still alive and all the attributes are still displayed. Replication is doing the job!
Tomcat + Apache2/mod_jk + memcached-session-manager
This is a more interesting and newer scenario. For this configuration I decided not to use memcached (like MSM expects) but membase. Membase is a next generation memcached with several improvements (mainly because it is not a cache, it is a real NoSQL database which stores data in disk, has replication features and manages topology changes) but keeps all goodness (simplicity, elasticity, very fast,...).
The main reason for this change is how I understand this solution. For me the external repository must handle HA independently and memcached is just a cache system, it does not cover replication or even a server fault (for this reason MSM stores a second backup session when more than one memcached is configured). But membase uses the idea of buckets, which are isolated virtual containers for data and they are currently of two types: memcached (same old characteristics) or membase type (new features of persistence, replication and rebalancing). Actually membase does not perform an automatic rebalancing, if a server fails an administrator must rebalance the cluster manually via the web console or via script (semi-automatic rebalancing). In my opinion for session storage the persistence part (saving data in disk) is not necessary, although sessions can survive through membase reboots I think the cost is greater than the benefits. So if membase had a bucket with only replication and rebalancing I think it would be the best configuration for this goal. Think about that, a membase without disk storage is the perfect extension of the second scenario, session is replicated only the configured times (in a membase cluster you can set how many copies are saved) and space is not wasted in all tomcats. Of course there are some disadvantages like tomcat accesses to membase every request (but membase is supposed to be very fast) and partial replication is not possible (membase is a general purpose repository so it does not know anything about sessions or attributes). But, in general, I think a in-memory replicated repository could be the best solution for an architecture with a lot of servers, a lot of sessions or very big ones.
As I said MSM is thought to be configured against, at least, two memcached servers (one for main session storage and the second as a backup if the first one fails) but I will only configure one (membase replicates information instead of MSM). Clients for membase can be of two types (see membase types of clients) and MSM uses the spymemcached library which is of type 1 (typical memcached client which is not aware of cluster topology). For this situations membase deploys a gateway process (called moxi) which is the responsible of redirect the requests to the correct membase server (for more information about moxi gateway see membase documentation). So finally I setup a two node membase cluster (one in each debian box), with default membase type bucket (one extra copy configured) and each tomcat instance accesses the server-side moxi. The membase software was installed using community 64bit debian package downloaded from couchbase site. MSM was configured following its beautiful and simple guide, I used non-sticky configuration (although I use sticky mod_jk workers I wanted that sessions were always retrieved and stored) and kryo recommended serialization.
As usual my setup fell into a MSM bug, a lot of objects remained in membase when sessions were invalidated (they are not removed). The problem seemed to be that the code always tried to delete the backup session object although it had not been created previously (cos only one memcached is configured), it thrown an exception and other object was not removed (MSM stores two objects per session). I fixed the problem and, as usual, I try to be a friendly neighbor and I sent an email to MSM main developer explaining my case (Martin Grotzke kindly opened an issue for me).
After the bug was fixed a membase session storage system was correctly working. Now the sessions are always retrieved and then saved from/to membase on every client request to tomcat. So now in the video when the server is killed the other one successfully retrieves the session from membase and the attributes are still there. But even better, if I kill both Tomcats and I start the first one killed my session is still active (cos membase stores it outside tomcat). In the membase statistics page for default bucket the new session objects has been created.
I also wanted to test a JDBC solution (in order to have a comparison with previous SQL backends) and I tried to configure tomcat JDBC Store and the Persistence Manager with MySQL (I tried to follow this guide). But it did not work for me. Although sessions survived through tomcat restarts they were almost never persisted when tomcat was killed. It seemed like sessions were not always stored inside the table and they were just inserted based on a time scheduling. In short I was not able to make sessions to be inserted immediately in the database (if someone is smarter than me please comments will be appreciated). And I have to admit this point is a real pity for the next point.
BENCHMARK
Finally I set up a benchmark to test the three scenarios. As I commented the ServletBenchmark is a smart application that simulates a common web navigation (check the application link previously presented for details). In this case it was specially interesting cos this benchmark manages session with three different types of users:
- Short size (10 bytes) and short lived session (one request).
- Medium size (up to 150 bytes) and medium lived session (five requests).
- Long size (up to 2100 bytes) and long lived session (20 requests).
I prepared this JMeter test plan which launches 60 concurrent threads looping over the three ServletBenchmark cases for half an hour. In each loop the thread has 20% of probabilities to execute the short scenario, 30% the medium and 50% the long one. When the scenario is completed the thread sleeps for 1 second and then invalidates the session. Architecture is also very important for understanding any benchmark. And, as I explained before, my demo site is a crap: all inside my laptop; two KVM virtualized Debian Squeeze linux (apache2, tomcat and membase installed in each); the JMeter benchmark tool in my real Debian laptop pointing to the first apache. So it is clear numbers are not very important, just the difference between them.
You can download the complete results for the three scenarios (Load balancing, replication cluster and membase solution). And here they are the numbers via charts and graphics:
- Average response time and 90% Line time (response time in which the 90% of requests were completed) for the three solutions.
- JMeter graph results for the three scenarios.
- Membase statistics (screenshot of the default bucket statistics).
- CPU consumed (top used) by involved processes (in the third scenario tomcat and membase percents have been added). Two graphs, one for each debian box.







For me the results are exactly what I had in mind before the benchmark. First and important, there is no error in any of the tests, so the three solutions are very reliable. A thing that surprise me is that numbers are quite low (6, 7 and 11 ms for average response time respectively). This means KVM works really well and, maybe, as everything is deployed in the same physical box, communication latencies are nearly zero. If we look at the response times things work as expected. Each solution gives more availability than the previous one with a cost in performance. But this cost seems reasonable, only 1 ms in replication over simple load balancing and 4 ms in membase solution over replication cluster. And in the 90% line, distances remain the same (which means three solutions work quickly most of the times). When checking the CPU used, load balancing uses around 5-7% of the CPU time, replication over 12-14% and membase (tomcat + membase daemons) over 20-23%. They are also expected except that membase is a little more of what I thought, tomcat process itself is a bit more CPU hungry than in replicated scenario (cost of serialize the whole session) and membase processes (moxi, memcached and beam) add around 6-7% more.
Final comments, the benchmark has not stressed the system enough (I think I would have needed more threads, lower sleeping times or a more intense application but I also think that this is more than enough for what I wanted to show). The membase scenario is a really good competitor, cos a 4-5ms penalty is almost nothing in my opinion (think in a real scenario where requests do some real processing and can last for 100ms or more). And remember these numbers can be even lower if membase do not save sessions in disk. It was a real pity that the numbers of a real JDBC solution cannot be compared (seeing what is the real distance between new membase NoSQL solution and a traditional MySQL/PostgreSQL one would have been great). Of course this membase solution is not in a production ready state (there are some snags, mainly with membase HA) but the goal of this entry was testing if this kind of in-memory softwares are convenient as session stores (numbers have been presented) and, at the same time, checking some real open-source scenario.
I have invest some time in this benchmark but it was a thing I really wanted to do. I hope it was worthy for someone else. See you next time!
Comments