

Monday, October 25. 2010
Using Cassandra with EJB Technology

The past week Eric, a french reader of the blog, contacted me because of my old Cassandra entry. He was trying to get some help in how to implement an Enterprise Java Bean for the NoSQL database. As I explained in the Terminal Services posts the portlet used Thrift and Cassandra to store the application tree which was shown in the series. I am going to present the same solution but replacing the portlet with an EJB 3.1 / JSF 2.0 web application. The idea of this post is explaining the whole process.
First of all the Cassandra data model was designed. If you remember, the Terminal Services portlet is a tree very similar to a file system. Any item can be a folder or an application. Folders can contain any number of other folders or applications, and applications are leafs which contain the RDP definition file (the file which is downloaded to launch the Terminal Services client program). Following the ideas presented in the old Cassandra post only two simple columns were needed.
- Applications: The applications column family will contain all the applications and folders. The key will be the complete and uppercased path of the application (for example /APPLICATIONS/SKYPE) and the values will represent different data. More precisely the columns will be the following:
- name: application name to show (Skype).
- description: application description.
- icon: 16x16 PNG icon.
- type: app or folder.
- rdp: rdp file to startup this application (only for apps).
Applications: { // ColumnFamily
/INTERNET: { // key
name: Internet
description: Internet applications
icon: 0x19EA14...
type: folder
},
/INTERNET/SKYPE: { // key
name: Skype
description: VoIP client application (www.skype.com)
icon: 0x56FA12...
type: app
rdp: 0xA4326A...
}
...
}
- ApplicationStructure: This other column family just cover the folder structure which is missing in the other one. This column is quite simple, the key continues to be the path of the folder in uppercase and the values are its children (path and name of every child). This column family gives an easy way to access all the children of a specified folder.
ApplicationStructure: { // ColumnFamily
/APPLICATIONS: { // key
/APPLICATIONS/INTERNET: Internet
/APPLICATIONS/PAINT: Paint
},
/APPLICATIONS/INTERNET: { // key
/APPLICATIONS/INTERNET/PIDGIN: Pidgin
/APPLICATIONS/INTERNET/SKYPE: Skype
}
...
}
In order to create the EJB which manages applications (and folders) the idea is just creating a bean which handles basic CRUD operations for applications. This class is called CassandraManagerEJB. In the previous posts this class was a POJO (liferay was deployed inside a tomcat and EJB technology was unavailable) that has been now converted into a Singleton Enterprise Bean. Another class called Application represents any application or folder with typical getters and setters. Obviously the CassandraManagerEJB receives objects of this class and transforms them into thrift mutations and columns for writing and vice-versa for reading. There is a special folder keyed by "/" for the root path. The EJB uses commons-pool to treat Thrift connections inside a pool. The three main methods in the EJB are the following:
- readApplication: Reads any application from the Cassandra repository. The application or folder path is passed to the method. The attributes to read can be also specified in order to not read all of them. But it also receives a parameter to specify how the children is retrieved:
- NONE: No children are returned, the column family Applications is the only one read.
- ONLY_NAMES: The application is also read from the ApplicationStructure column family and only its data is filled in the children list (path and name).
- FULL: After reading the children from ApplicationStructure all of them are also got from the Applications column family. So now all the specified attributes are filled in the children list.
- RECURSIVE: The method is called recursively to retrieve all hierarchy with all attributes specified, from the path passed to the bottom.
- createApplication: Creates or updates an application or folder. This method do not let create folders with children (for folders is just like mkdir command), application names cannot contain '/' character (only root can do that) and the specified parent must exists previously in Cassandra repository. If the application object passed does not follow these rules an Exception is thrown.
- deleteApplication: Deletes an application or folder. If the application does not exist or it is a folder with children the method throws an exception (again it can be considered like a rmdir command in case of a folder).
I tested the web module deploying it inside a J2EE6 compatible glassfish v3 application server. So the EJB is annotated to be a Singleton and an application scoped named object, this way the EJB can be injected using Context Dependency Injection (CDI). Remember the beans.xml file must be created to make WELD (CDI implementation) start to work. I recommend to read this post to know more about the differences between CDI and EJB injecting techniques.
The JSF part will use the created enterprise bean to display all the tree. There is only one managed bean which is called ApplicationTreeBean but it is accompanied by some helper classes. This JSF bean uses injection to get the Singleton EJB and is also annotated as named to be injected into index.xhtml facelet like a session scoped bean. The JSF part can be more or less complicated but it just presents the application tree we saw in the Terminal Server entries (see image below).
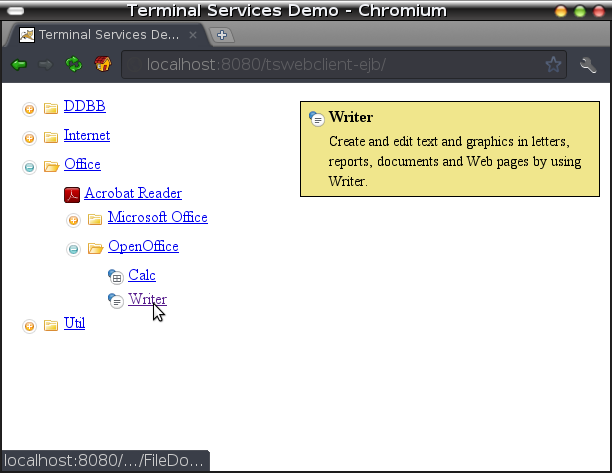
As all of you can see this way of integrating Cassandra into EJB 3.1 technology is very very straight forward but, not being an expert in Cassandra, I think it is the most suitable nowadays. Remember all Cassandra stuff presented here uses the inflexible Thrift client (I chose it cos I wanted to learn Cassandra internals), there are some more java clients out there and surely they are friendlier. Here it is the whole Netbeans project just in case (libraries have been deleted to save space).
When I talked all this stuff to Eric, he advised me there is a project called Kundera (I have just realized it is listed as Cassandra client in the previous link) which is trying to implement a JPA provider for Cassandra (see the following post). At first moment I think it makes no sense, the Java Persistence API is tightly coupled with SQL (it can be said it was designed to cover SQL databases) and, therefore, not very suitable for a NoSQL repository like Cassandra. The weekend I spent some time trying to figure out how, for instance, the queries are performed. Kundera mixes Cassandra repository with Lucene indexing engine and, this way, some little queries can be performed against the indexes. Looking into relations (many to many, one to many, one to one,...) I saw some of them are still not implemented, but this point is less problematic cos developers could (more or less) follow the same ideas I commented in my previous entry about Cassandra. So, despite of my initial skepticism, the project has at least some sense. I still believe the idea is a bit farfetched but I have to admit they are implementing the same solution I would have used in a supposed Cassandra project. If you remember I already talked about mixing Cassandra and some indexing engine like solr (Lucene based) to get a robust result.
Good job guys! Continue surprising me!
Sunday, April 25. 2010
Getting Started With Cassandra
Cassandra is a highly scalable second-generation distributed database which stores data in a kind of hash map model. Let's start with it.
CONCEPTS
The main data model concepts realated to Cassandra are the following:
- Cluster: As a distributed database Cassandra can be conformed by several machines or nodes. All of them act as a single Cassandra cluster. Data is distributed and replicated among cluster nodes.
- Keyspace: A cluster contains one or more keyspaces. A keyspace is just a group of column families that logically act together (usually every application has its own keyspace).
- Column family: A column family is a large set of columns. It is easy to compare a column family to a big hash map where keys are strings and the values are column rows. The columns for a key are sorted in a specified, defined way. A column family can contain columns or super columns (never both).
- Column: The column is the smallest piece of information in Cassandra model. Each column is a triplet of name, value and a timestamp. Sorting always affects only names (column families sort by names). Timestamp part of the column cannot be used for informational purposes, Cassandra uses them for internal functionality.
- Rows: A lot of times in Cassandra the term rows is heard. In my understanding rows are not more than a group or list of columns. This way Cassandra talks about row keys (the string which is the key in a column family), result rows (columns returned from a key),...
- SuperColumn: A super column is a special type of column which value is a (sorted) associative array of columns and has no timestamp. A super column can be compared to a hashmap of hashmaps. It is important to understand that a super column family sorts data twice, first names of the super column and then, for each super column value its column rows are sorted by name again.
- Sorting: An important point in Cassandra is sorting, column rows are sorted for every key and always by column name. There are some pre-defined types of sorting like BytesType, UTF8Type, LexicalUUIDType, TimeUUIDType, AsciiType, or LongType but custom sorting can be done extending org.apache.cassandra.db.marshal.AbstractType class. Super columns has two types or sorting, one for super column names, and other for sub-column names in rows value.
DATA MODEL
When you face Cassandra for the first time it is quite complex how to model a specified problem or reality. It was specially useful for me this entry from Arin Sarkissian's blog which makes a blog example data model. Please read Arin's entry before continuing for a complete understanding.
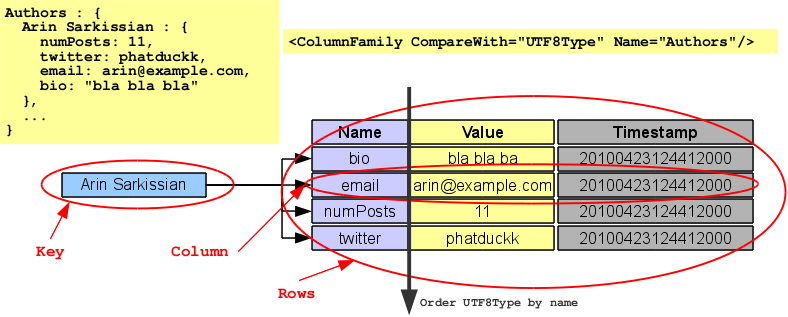
Using Arin's example I will try to consolidate the concepts commented before. The first column family Authors is just a normal (not super) column family. Keys for this family are the author full names and every author/key has some columns to store some info about him (email, twitter nickname or whatever). In the example rows for each key are sorted using BytesType comparison but for teaching purposes I will use UTF8Type sorting. This way the first column family can be represented with the following drawing.
The only super column family in Arin's example is presented at the end, Comments is a super column. The row key for the super column is the blog entry slug, the super columns are the comments for the blog entry. Each super column has the timestamp (the time when the comment was done) as name and the values are the data of each comment as column rows (commenter, commenter email, comment text itself,...). It is important to understand the sorting, comments inside an entry are sorted using TimeUUIDType (time order, newer first) and data inside comments using BytesType (again I have change that to UTF8Type to clarify). So comments super column looks like this.
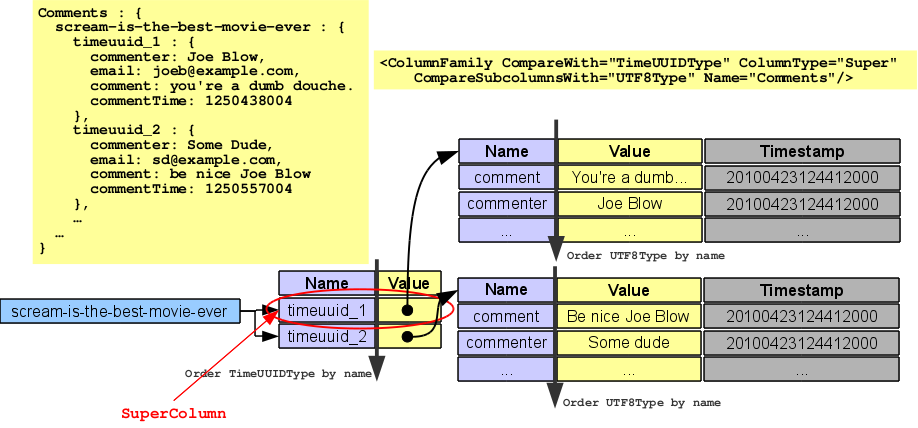
I hope the drawings make column and super column concepts clearer.
And that's all folks. Cassandra data model has no more to play with, our application repository has to be a bunch of column (normal or super) families sorted in a predefined way and grouped inside a keyspace. Developers who are used to working with SQL will presumably have some problems, so some rough translations are presented.
- Entity: An entity or table can be direct translated to a column family. For example Authors or BlogEntry in Arin's data model. My example is a more generic people entity.
People: {
John Dow: {
twitter: jdow,
email: jdow@example.com,
bio: bla bla bla,
...
},
}
- One to One Relation: A one to one relation can also be defined inside the same entity column family. For example, using people column family the married to relationship is just another column value for the key.
People: {
John Dow: {
twitter: jdow,
email: jdow@example.com,
bio: bla bla bla,
marriedTo: Mary Kay,
...
},
Mary Kay: {
marriedTo: John Dow,
...
},
...
}
- One to Many Relation: For a one to many relation it seems a good idea to create another column family. For example if children information must be provided for the previous example, we can add the following column family children.
Children: {
John Dow: {
01/18/1976: John Dow Jr,
05/27/1982: Kate Dow
},
...
}
As you see the children information is in another column family and it is sorted by the birth date. One important thing in Cassandra is both name and value can be used with no difference to represent data but only name is sorted. If the access from children to parents is also needed it can be done like in a one to one relation.
People: {
John Dow Jr: {
father: John Dow,
...
},
...
}
- Many to Many: In a many to many relation it is common to use again two new column families (if access from both entities is required). For example in a friendship relation.
Friendship: {
John Dow: {
10: Mark Seldon,
8: Julian Hendrix,
...
},
Mark Seldon: {
9: John Dow,
...
},
...
}
In the example there is only one column family cos the relation is between characters of the same entity people (but each relation affects two keys). And in my example the sorted column name is the degree of friendship between them (from 0 to 10).
- Weak entities: When the relation involves a weak entity we can use a super column family. The clear example is the comments family in Arin's entry (comment is a weak entity that depends on BlogEntry). Following our example, if we need to store the car(s) of our people we can assume cars as a weak entity:
Cars: {
John Dow: {
6CVW063: {
model: chevrolet beat,
color: blue,
...
},
4FYB066: {
model: chevy equinox,
color: white,
...
},
...
}
- Indexes: One of the biggest problem when moving from SQL to Cassandra is now selects cannot be performed. Indexes are now restricted to sorted column names, so applications are less flexible. But again required filters must be represented as column families.
For example if we need to select people for a special locality we can add a locality column family for our people:
People: {
John Dow: {
locality: New York,
...
},
...
}
Locality: {
New York: {
John Dow: 3 East 40th Street,
...
},
...
}
Other tricky techniques can be used (as Arin says never be afraid of denormalization using Cassandra), for example we can create a column keyed by words of the fullnames of our people, this way we have a kind of indexer:
PeopleNames {
JOHN: {
John Dow: JOHN|DOW,
John Dow Jr: JOHN|DOW|JR,
...
},
DOW: {
John Dow: JOHN|DOW,
John Dow Jr: JOHN|DOW|JR,
...
},
...
}
But, of course, if a very complex search engine is needed the application should mix Cassandra repository with a indexer/search solution like solr. Nowadays it is quite common indexing DDBB data, this way application has a very, very flexible search engine independent of the repository (NoSQL, SQL, LDAP or whatever). Looking to Arin's blog example, the TaggedPosts column family represents a kind of index (tags classify blog entries and let users to access directly this type of entries) but as a blog solution a indexer of the entries would surely be involved.
INSTALLATION
Cassandra instalation is very easy (at least for my testing purposes) and I followed the instructions of Mike Peters. In my debian laptop I had a problem with ipv6 and I manually set the following java property -Djava.net.preferIPv4Stack=true in cassandra booting script to fix the problem.
CODING
Last part of my Cassandra introduction was coding. One of my future posts deals with a kind of File System structure (applications inside folders to show a menu) and I decided to use Cassandra instead of a traditional SQL DDBB. That is the reason of my little study about Cassandra.
Cassandra uses Thrift as client (although there are some high level Java clients I did not use them). Thrift is a generic cross-language framework to develop services. For Cassandra integration thrift must be compiled (the same link commented in installation part talks about thrift compilation and installation). Thrift examples for a lot of languages are shown in Cassandra site and the complete API is also explained in detail. I only tested thrift with Java language using Cassandra 0.6 versions.
- Make a connection. Thrift only lets one client per socket so pooling should be considered.
Cassandra.Client client = null;
try {
TTransport tr = new TSocket("localhost", 9160);
TProtocol proto = new TBinaryProtocol(tr);
client = new Cassandra.Client(proto);
tr.open();
// keyspace, column family and key
String keyspace = "keyspace1";
String columnFamily = "columnFamily1";
String key = "key1";
// do the work
// ...
} finally {
if (client != null) {
client.getOutputProtocol().getTransport().close();
}
}
- Inserting columns for a key. Cassandra guarantees reads and writes to be atomic within a single ColumnFamily. So all columns you write in the same column family in a batch_mutate are atomically performed. From my point of view it would be nice all batch_mutate was atomic, this way operations made in different column families (relations) but in the same call would be consistent (see Cassandra architecture overview for more details).
// create a list of columns to insert using mutate
List<Mutation> mutList = new ArrayList<Mutation>();
// first column
Column col = new Column("name1".getBytes("UTF8"),
"value1".getBytes("UTF8"), System.currentTimeMillis());
ColumnOrSuperColumn cosc = new ColumnOrSuperColumn();
cosc.setColumn(col);
Mutation mut = new Mutation();
mut.setColumn_or_supercolumn(cosc);
mutList.add(mut);
// second column
col = new Column("name2".getBytes("UTF8"),
"value2".getBytes("UTF8"), System.currentTimeMillis());
cosc = new ColumnOrSuperColumn();
cosc.setColumn(col);
mut = new Mutation();
mut.setColumn_or_supercolumn(cosc);
mutList.add(mut);
// more columns??
// create the map of column family => mutations
Map<String,List<Mutation>> mapCF = new HashMap<String,List<Mutation>>(1);
mapCF.put(columnFamily, mutList);
// create the map row key => column family => mutations
Map<String, Map<String, List<Mutation>>> muts =
new HashMap<String, Map<String, List<Mutation>>>(1);
muts.put(key, mapCF);
// insert all the mutations for this key in all the column families
client.batch_mutate(keyspace, muts, ConsistencyLevel.ANY);
- Reading columns from a key.
// create a predicate to read all columns for the key
SlicePredicate predicate = new SlicePredicate();
SliceRange sliceRange = new SliceRange();
// all columns, no start or finish
sliceRange.setStart(new byte[0]);
sliceRange.setFinish(new byte[0]);
predicate.setSlice_range(sliceRange);
ColumnParent parent = new ColumnParent(columnFamily);
List<ColumnOrSuperColumn> cols = client.get_slice(keyspace,
key, parent, predicate, ConsistencyLevel.ONE);
for (ColumnOrSuperColumn cosc: cols) {
Column column = cosc.column;
String colName = new String(column.name, "UTF8");
String colValue = new String(column.value, "UTF8");
// do something...
}
- Deleting columns from a key.
// create a predicate to delete
SlicePredicate predicate = new SlicePredicate();
// now thrift predicate does not accept slices for mutation delete
// so use column names
predicate.addToColumn_names("name1".getBytes("UTF8"));
predicate.addToColumn_names("name2".getBytes("UTF8"));
Deletion deletion = new Deletion();
deletion.setPredicate(predicate);
deletion.setTimestamp(System.currentTimeMillis());
// create the mutation for deleting
Mutation mutation = new Mutation();
mutation.setDeletion(deletion);
List<Mutation> delData = new ArrayList<Mutation>(1);
delData.add(mutation);
Map<String,List<Mutation>> map = new HashMap<String,List<Mutation>>(1);
map.put(columnFamily, delData);
Map<String, Map<String, List<Mutation>>> muts =
new HashMap<String, Map<String, List<Mutation>>>(1);
muts.put(key, map);
client.batch_mutate(keyspace, muts, ConsistencyLevel.ANY);
- Inserting a super column with data. Very similar to insert columns, a super one is just treated as columns but with two level of information.
// create a list of columns to assign to the super column
List<Column> columns = new ArrayList<Column>();
// add some columns values
columns.add(new Column("name1".getBytes("UTF8"),
"value1".getBytes("UTF-8"), System.currentTimeMillis()));
columns.add(new Column("name2".getBytes("UTF8"),
"value2".getBytes("UTF-8"), System.currentTimeMillis()));
// create the super column with the columns as value
SuperColumn superColumn = new
SuperColumn("supername1".getBytes("UTF8"), columns);
ColumnOrSuperColumn cosc = new ColumnOrSuperColumn();
cosc.setSuper_column(superColumn);
// create the mutation list
List<Mutation> mutList = new ArrayList<Mutation>();
Mutation mut = new Mutation();
mut.setColumn_or_supercolumn(cosc);
mutList.add(mut);
// assign column family => mutations
Map<String,List<Mutation>> mapCF = new HashMap<String,List<Mutation>>(1);
mapCF.put(columnFamily, mutList);
// create the map row key => column family => mutations
Map<String, Map<String, List<Mutation>>> muts =
new HashMap<String, Map<String, List<Mutation>>>();
muts.put(key, mapCF);
// insert all the mutations for the super column
client.batch_mutate(keyspace, muts, ConsistencyLevel.ANY);
Now I am ready to start my little Cassandra modeled portlet.
Enjoy!
Comments