

Saturday, April 30. 2011
JAX-WS and Multiple Endpoints

These last weeks I have been working in an identity project that deals with Web Services. The customer wants the Identity Solution to integrate several applications via Web Services. Therefore the agreement of a WSDL between all parts was the first issue to work with. The WSDL (Web Services Description Language) is an XML language to describe and model Web Services, using simpler words, it is a way to define what methods to implement and what the data model exchanged is (without any doubt). Finishing the introduction JAX-WS (Java Api for XML Web Services) is the API that deals with Web Services as part of the Java EE platform specification (it gives annotations, WSDL parsing and many other features to simplify the development of Web Services in the Java platform).
It is important to explain that in this case my part (the identity side) would be the client whilst the different applications would be the Web Services server side. This way the Identity Software would invoke the methods of the agreement in order to provision a new account, to change some attributes or to delete a user in the integrated application. If a WSDL is defined previously no compatibility problems are expected, no matter the server software or the implementation language. Besides, as all methods and exchange objects had been deliberately defined generic, only one client would have been needed in the identity side for all applications. In fact the agreement document version 1.0 (with the first version of the WSDL inside too) was sent to customer and to the different application teams some months ago.
But people sometimes do not understand what a WSDL is and, even worse, developers think some methods with similar functionality are more than sufficient (which is basically true but it converts all the previous work in a waste of time and the scheduled timetable in a real bullshit). Of course these little modifications are considered not important enough to even advise the other parts involved. To sum the first application to integrate had developed their way Web Services. Besides the application team used a custom and abominable Web Services framework which did not generate the artifacts, so the XML data had to be manually parsed (oh my gosh!). Another of its features was every operation was bound to a different endpoint (a different URL). Needless to say the WSDL was not automatically generated and it had also to be written manually. So you can image the situation. After some crisis times I decided to tune their WSDL and implement the same file in a modern application server, mainly my idea was testing with a confident implementation and reporting errors to them as fast as I can.
But developing a multi-endpoint web service with JAX-WS was not as easy as I expected and this is the reason for this entry. I decided to use Metro implementation which is the JAX-WS reference and open-source implementation done by Oracle (formerly Sun). Actually metro is the complete Web Services stack for glassfish (and other application servers) and covers many other components like JAX-RS (see my ScatterPlot entry for more information for RESTful Web Services), JAXB, WSIT or SAAJ inside the Java EE. There are more implementations like Apache Axis 2, Apache CXF or Codehouse XFire but I have more experience with this one and I suppose basics are the same for all of them. I spent some time to create the Web Service and I want to save this information here.
For obvious reasons I cannot present the real WSDL file so I created a very simple user CRUD service for a supposed application, here it is the basic-crud.wsdl file. This WSDL is not generic but it is easier and better for learning purposes. The definition has four endpoints with one operation inside each (Create, Read, Update and Delete). If you download the JAX-WS Metro bundle there are some sample applications inside, and one of them explicitly shows how to create a jax-ws service from a given WSDL file (fromwsdl inside samples directory). Following the instructions the wsdl must be imported in order to create the interfaces and exchange objects:
$ wsimport -keep -Xnocompile -verbose -d ../../../src/java/ basic-crud.wsdl parsing WSDL... generating code... sample/user/crud/basic/CreatePort.java sample/user/crud/basic/CreateRequest.java sample/user/crud/basic/CreateResponse.java sample/user/crud/basic/DeletePort.java sample/user/crud/basic/DeleteRequest.java sample/user/crud/basic/DeleteResponse.java sample/user/crud/basic/ObjectFactory.java sample/user/crud/basic/ReadPort.java sample/user/crud/basic/ReadRequest.java sample/user/crud/basic/ReadResponse.java sample/user/crud/basic/SampleUser.java sample/user/crud/basic/Status.java sample/user/crud/basic/StatusCode.java sample/user/crud/basic/UpdatePort.java sample/user/crud/basic/UpdateRequest.java sample/user/crud/basic/UpdateResponse.java sample/user/crud/basic/WsCRUDUserService.java sample/user/crud/basic/package-info.java
The wsimport command parses the WSDL file and generates the Java portable artifacts (keep option does not delete the Java files and they are saved inside src directory). With this command all Java classes and the Web Service Interfaces are generated for all the ports. After that the different ports need to be coded and, following the fromwsdl example, the @WebService annotation must only have the endpointInterface property set in each. In my example all the ports just manage the users into memory (a memory example repository). The code for read operation is presented below.
package sample.user.crud.basic.implementation;
import javax.jws.WebService;
import sample.user.crud.basic.ReadRequest;
import sample.user.crud.basic.ReadResponse;
import sample.user.crud.basic.SampleUser;
import sample.user.crud.basic.Status;
import sample.user.crud.basic.StatusCode;
@WebService(endpointInterface = "sample.user.crud.basic.ReadPort")
public class ReadPort {
private UserMapSingleton map = UserMapSingleton.getSingleton();
public ReadResponse read(ReadRequest request) {
ReadResponse response = new ReadResponse();
Status status = new Status();
response.setStatus(status);
try {
if (request.getId() == null) {
status.setStatus(StatusCode.ERROR);
status.setMessage("No ID passed!");
} else {
SampleUser user = map.getMap().get(request.getId());
response.setUser(user);
status.setStatus(StatusCode.OK);
if (user == null) {
status.setMessage("User '" + request.getId() + "' not found!");
}
}
return response;
} catch (Throwable t) {
status.setStatus(StatusCode.ERROR);
status.setMessage(t.getMessage());
return response;
}
}
}
When the Web Services are created from a defined WSDL all the ports have to be added to the sun-jaxws.xml file manually (as I said previously only the endpointInterface attribute annotation is present in the Java class and all the configuration is defined via the sun-jaxws file). This file contains all the endpoints with the implementation and interface part. You have to think this is exactly the opposite of what is done when the WSDL is not previously defined (everything is annotated and nothing is set in the sun-jaxws.xml). Here it is the file for the four CRUD endpoints.
<endpoints
xmlns="http://java.sun.com/xml/ns/jax-ws/ri/runtime"
version="2.0">
<endpoint
name="wsCRUDUserServicePortTypeBindingCreate"
implementation="sample.user.crud.basic.implementation.CreatePort"
interface="sample.user.crud.basic.CreatePort"
wsdl="WEB-INF/wsdl/basic-crud.wsdl"
service="{http://basic.crud.user.sample}wsCRUDUserService"
port="{http://basic.crud.user.sample}wsCRUDUserServicePortTypeBindingCreate"
url-pattern="/wsCRUDUserServicePortTypeBindingCreate" />
<endpoint
name="wsCRUDUserServicePortTypeBindingRead"
implementation="sample.user.crud.basic.implementation.ReadPort"
interface="sample.user.crud.basic.ReadPort"
wsdl="WEB-INF/wsdl/basic-crud.wsdl"
service="{http://basic.crud.user.sample}wsCRUDUserService"
port="{http://basic.crud.user.sample}wsCRUDUserServicePortTypeBindingRead"
url-pattern="/wsCRUDUserServicePortTypeBindingRead" />
<endpoint
name="wsCRUDUserServicePortTypeBindingUpdate"
implementation="sample.user.crud.basic.implementation.UpdatePort"
interface="sample.user.crud.basic.UpdatePort"
wsdl="WEB-INF/wsdl/basic-crud.wsdl"
service="{http://basic.crud.user.sample}wsCRUDUserService"
port="{http://basic.crud.user.sample}wsCRUDUserServicePortTypeBindingUpdate"
url-pattern="/wsCRUDUserServicePortTypeBindingUpdate" />
<endpoint
name="wsCRUDUserServicePortTypeBindingDelete"
implementation="sample.user.crud.basic.implementation.DeletePort"
interface="sample.user.crud.basic.DeletePort"
wsdl="WEB-INF/wsdl/basic-crud.wsdl"
service="{http://basic.crud.user.sample}wsCRUDUserService"
port="{http://basic.crud.user.sample}wsCRUDUserServicePortTypeBindingDelete"
url-pattern="/wsCRUDUserServicePortTypeBindingDelete" />
</endpoints>
Finally the web.xml is modified to add JAX-WS listener and servlet and the servlet is mapped against all the URLs specified in the previous file.
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.5" xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd">
<listener>
<listener-class>
com.sun.xml.ws.transport.http.servlet.WSServletContextListener
</listener-class>
</listener>
<servlet>
<display-name>wsCRUDUserService</display-name>
<servlet-name>wsCRUDUserService</servlet-name>
<servlet-class>com.sun.xml.ws.transport.http.servlet.WSServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>wsCRUDUserService</servlet-name>
<url-pattern>/wsCRUDUserServicePortTypeBindingCreate</url-pattern>
<url-pattern>/wsCRUDUserServicePortTypeBindingRead</url-pattern>
<url-pattern>/wsCRUDUserServicePortTypeBindingUpdate</url-pattern>
<url-pattern>/wsCRUDUserServicePortTypeBindingDelete</url-pattern>
</servlet-mapping>
<session-config>
<session-timeout>30</session-timeoutv
</session-config>
<welcome-file-list>
<welcome-file>index.jsp</welcome-file>
</welcome-file-list>
</web-app>
In theory at this point everything is set and the project is ready to be used. I deployed the war file inside a standard glassfish 2.1.1 application server. If you access to any of the four mapped endpoints Metro lists all the endpoints defined in the application (see screenshot below). If the WSDL is requested to any of the four endpoints the same XML file is returned (cos four endpoints are coded from the same WSDL file).
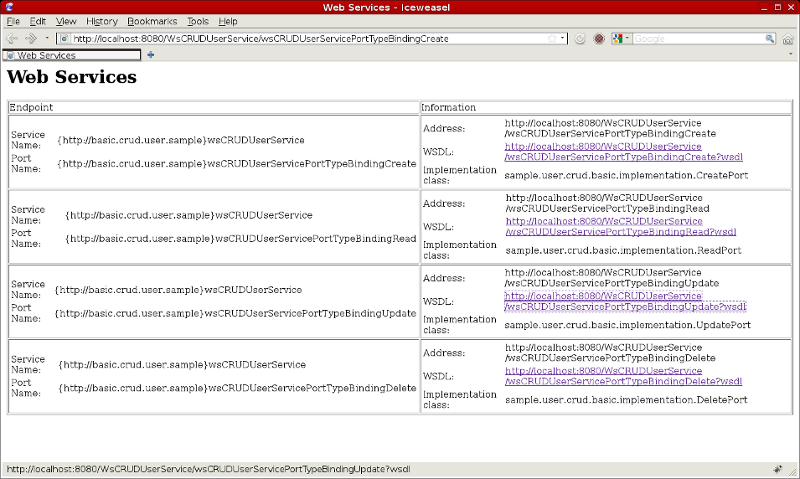
Finally I implemented a quick JUnit test case class which checks the four endpoints work as expected (it creates, updates and deletes a user doing some reads between modify operations to test the functionality).
Today's entry explains how to create a JAX-WS Web Service with several endpoints from a pre-defined WSDL definition file using reference Metro implementation. As you have stated it is not very difficult and you can directly follow fromwsdl sample instructions. But I wanted to summarize the process here to have a quick guide for the next time (I do not usually work with Web Services this way and I spent some time to achieve it). In my defense, it seems incredibly simpler once you have written the full instructions, these things always make me think I am really stupid  . The complete NetBeans project can be download from here.
. The complete NetBeans project can be download from here.
God is in the detail. Cheerio!
Sunday, April 10. 2011
Glassfish Enterprise Profile on Linux amd64


The previous week an ex co-worker, and a good friend, asked me if I had tested Glassfish 2.1.1 on a x64 linux box. The question surprised me cos my new laptop is an amd64 Linux installation, all my glassfish tests are done in it and I had not noticed any problem. He clarified me that he could not setup an enterprise profile. I remember that Glassfish 2.1.1 has no difference between open source and supported edition (it was based on the same source code), so this entry is about how to setup a Glassfish enterprise profile in Linux x64 using its community version.
Glassfish v2 can be installed using three different profiles: developer, cluster or enterprise. Developer profile is a single application server instance. Cluster is a multi-instance setup with central management for all servers and cluster/Load Balancing features enabled. Enterprise profile is exactly like cluster but using NSS (Netscape Security Services) instead of JKS (Java KeyStore) for the certificate store and the possibility of using HADB for session management (a kind of multinode database that Sun used to integrate with Glassfish to get the third type of session-aware cluster I talked about in a previous post). My friend explained to me that the problem was with NSS libraries (supported Glassfish edition includes them), the libraries provided by the Linux distribution were ELF 32-bit and, obviously, they do not work with a 64 bit JVM and system.
I am going to explain the steps I followed testing this issue. This is usually how I like to show my entries, because I think this way is more useful and it is also better for me to remember.
-
As the Glassfish documentation comments, in open source edition NSS and NSPR libraries have to be installed independently from glassfish. In my debian box this step was easily done.
$ apt-get install libnss3-1d libnss3-tools libnspr4-0d libnspr4-dev libnss3-dev
Developer packages were not needed at this time but following points are going to use them.
-
Glassfish installer for open source edition was downloaded from glassfish site. For linux only one package is available. Cluster setup was installed using glassfish instructions.
$ java -Xmx256m -jar glassfish-installer-v2.1.1-b31g-linux.jar $ cd glassfish $ lib/ant/bin/ant -f setup-cluster.xml
Glassfish community edition is installed in the directory where the installer is launched, inside a new glassfish folder (this installation directory will be denoted ${GLASSFISH_DIR} since now). By default the previous process creates a domain (domain1) using cluster profile (not enterprise). So this domain was deleted.
$ cd ${GLASSFISH_DIR}/bin $ ./asadmin delete-domain domain1 -
The configuration file ${GLASSFISH_DIR}/config/asenv.conf was modified to include where NSS are installed (debian installs main NSS and NSPR libs in /usr/lib). So the following properties were modified:
AS_NSS="/usr/lib" AS_NSS_BIN="/usr/bin"
-
If you try to create an enterprise profile domain just like this the issue explained by my colleague happens. It seems a internal libasnss.so is also used and glassfish only provides it in 32 bit mode (as you see in the download page there is no Linux x64 installer). But this is open source so, not wasting any time, I took a look to glassfish 2.1.1 subversion and I found a nssstore.c file. This is a Java Native Interface (JNI) wrapper above NSS library (Java can call native libraries using JNI and this file is a wrapper to make the interaction easier). Although there are some links for completely building glassfish (one for glassfish v3 and another outdated one for v2), I quickly gave up because the process seems to be huge. So I decided to only compile the problematic file.
First the directory that contains this file was checked out:
$ cd /tmp $ svn checkout https://svn.java.net/svn/glassfish~v2/trunk/appserv-native-ee $ cd appserv-native-ee/src/cpp/nssutil/
After that the header file has to be made. In JNI this is done reading the class and executing javah command on it (the problematic class, source of the exception, was com.sun.enterprise.ee.security.NssStore).
$ javah -classpath ${GLASSFISH_DIR}/lib/appserv-se.jar \ -o com_sun_enterprise_ee_security_NssStore.h com.sun.enterprise.ee.security.NssStoreWith this header the C file can be compiled against NSS/NSPR debian 64 bits libraries:
$ gcc -fpic -I/usr/lib/jvm/java-6-sun-1.6.0.24/include/ \ -I/usr/lib/jvm/java-6-sun-1.6.0.24/include/linux/ \ -I/usr/include/nss/ -I/usr/include/nspr/ nssstore.c -c $ gcc -shared -Wl,-rpath,${GLASSFISH_DIR}/lib -o libasnss.so nssstore.o -lc \ -L/usr/lib -lnss3 -lnspr4 -lnssutil3 -lsmime3The new libasnss.so library is copied to glassfish lib directory (a backup is previously done).
$ cp ${GLASSFISH_DIR}/lib/libasnss.so ${GLASSFISH_DIR}/lib/libasnss.so.ORIG $ cp libasnss.so ${GLASSFISH_DIR}/lib/libasnss.so -
After the previous step the domain is successfully created but it fails to start. It complains about library /usr/lib/amd64/libsoftokn3.so does not exist. Looking again the code of the class EESecuritySupportImpl.java (thrower of the new exception) it tries to initialize the PKCS11 provider (method initNSS) with the libsoftokn3 NSS library compounding its path as follows: the AS_NSS path from asenv.conf (in our case /usr/lib), the architecture if system is 64 bits (amd64 in our case) and finally libsoftokn3.so if system is not windows. So the result is /usr/lib/amd64/libsoftokn3.so but, in case of debian, this library is located in /usr/lib/nss.
I did not think too much and, after becoming root, I created a link.
# cd /usr/lib # ln -s nss amd64
-
Finally the enterprise domain was created and started successfully.
$ cd ${GLASSFISH_DIR}/bin $ ./asadmin create-domain --profile enterprise --user admin --adminport 9898 \ --savelogin=true --savemasterpassword=true domain1 $ ./asadmin start-domain
Here it is a video where the new domain is created and started (as you see my architecture is amd64, the certificate store is NSS and glassfish works perfect).

As a conclusion the glassfish installer for Linux is only provided in 32 bits. It works in x64 Linux system using developer and cluster profile cos a complete Java stack is used (no JNI library is needed) but it fails in enterprise. The enterprise profile uses NSS as the certificate store and a little libasnss.so (JNI library) is provided for easier integration, but it is only in 32 bit. In this entry the library was re-compiled in my amd64 box. Of course another problems could come out cos I did not test all the features and maybe more libraries are used (there are more native libraries in the lib glassfish directory and all of them are 32 bit).
That's the Way I Wanna Rock 'n' Roll!
Tuesday, April 5. 2011
High Availability in Application Servers (sequel)

In the previous entry a study about High Availability (HA) in Application Server was done. The main reason for this study was checking how proper an in-memory repository (like membase) is for session management. I found memcached-session-manager (MSM), a session manager for tomcat and memcached, and, for that, I performed a benchmark of the three typical HA solutions using tomcat. In the comments section Martin Grotzke (the main developer of MSM) pointed out that, if mod_jk had been configured sticky, the proper behavior of MSM was also to be sticky. I want to explain that my understanding of the third scenario (a external repository is used to save sessions) consists in that the new backend (JDBC, in-memory or whatever) has to be a complete replacement for session management. This way it should be accesseded twice in every request (first to get the session and then, if session is modified, to save changes). This is the reason I configured MSM non-sticky, but obviously this is the most demanding configuration and quite weird (sticky mod_jk but non-sticky MSM is something clearly useless in a real deployment). Finally I have included the complete sticky benchmark to compare all results fairly.
The MSM project page explains the differences between sticky and non-sticky configuration. When tomcat servers are accessed in a sticky way MSM can assume that, if it has an active session, the session is up to date (cos no other server can modify it). Therefore sticky MSM configuration saves all gets (except in the first request, when there is no active session it has to check if it was previously created in a failed server). Besides MSM seems to use only one object in sticky configuration and two in non-sticky (session itself is obviously always managed but a kind of validity object is also managed in non-sticky implementation), so this fact saves some gets and sets too. In summary, there is a lot less work to do in sticky than in non-sticky configuration. Do not forget a get/set also represents a serialization/de-serialization process.
The MSM/membase sticky solution presents the following numbers. I also show the same charts and graphs of the previous entry:
- Average and 90% Line time (four configurations).
- New graphic results from JMeter for sticky scenario.
- Membase statistics page for this new benchmark.
- CPU utilization in both virtual boxes (all scenarios).





If you see the numbers of sticky configuration (8ms average request time and 14ms for 90% line time) are very similar to the replication cluster, and half a way between simple load balancing and SMS non-sticky. It is quite logical, more or less, half of the work is not necessary. Looking at CPU percentage the new sticky architecture is around 16% (tomcat process consumes a bit less than in replication scenario but membase adds another 4%). So, again, everything is as expected and it is clear that when this solution was mature enough it would be very very competitive with replication cluster but more scalable. All the options have been benchmarcked and studied, as I said before, now it is fairer.
Cheerio!
Comments